Was ist der Shapiro-Wilk Test?
Der Shapiro-Wilk-Test ist ein statistischer Test, der dich wissen lässt, ob eine Datenstichprobe einer Normalverteilung folgt. In vielen statistischen Analysen wird angenommen, dass die Daten normalverteilt sind. Der Shapiro-Wilk-Test hilft dir dabei, diese Annahme zu überprüfen. Wenn die Daten nicht normalverteilt sind, könnten andere Tests oder Analysemethoden erforderlich sein. Der Test vergleicht die Ordnung deiner Daten mit der einer Normalverteilung. Wenn die Werte nah bei 1 liegen, sind die Daten wahrscheinlich normalverteilt. Liegen sie weit von 1 entfernt, ist die Annahme der Normalverteilung wahrscheinlich nicht erfüllt.
Wie wird der Shapiro-Wilk Test umgesetzt?
Umsetzung in R mit einem Beispiel
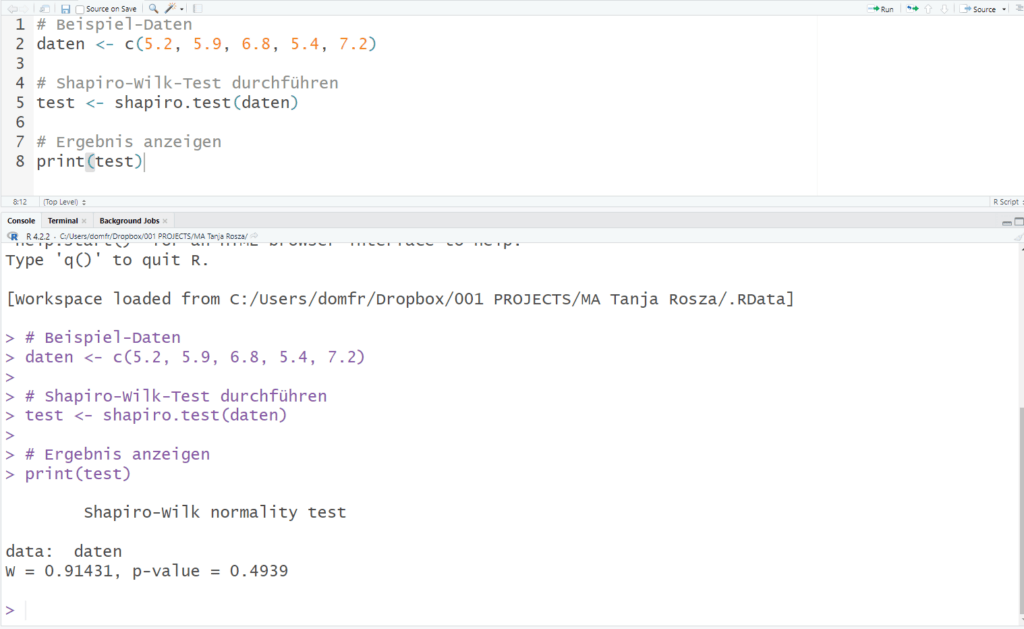
Du kannst den Shapiro-Wilk-Test in R leicht durchführen. Hier ist ein Beispiel:
# Beispiel-Daten
daten <- c(5.2, 5.9, 6.8, 5.4, 7.2)
# Shapiro-Wilk-Test durchführen
test <- shapiro.test(daten)
# Ergebnis anzeigen
print(test)
In diesem Fall erhältst du die W-Statistik und den p-Wert. Die W-Statistik gibt dir einen Wert, der sich dem Wert 1 nähert, wenn die Daten normalverteilt sind. Der p-Wert sagt dir, ob der Unterschied signifikant ist. Wenn der p-Wert größer als 0,05 ist, kannst du davon ausgehen, dass die Daten normalverteilt sind.
Umsetzung in SPSS
In SPSS kannst du den Shapiro-Wilk-Test durchführen, indem du diese Schritte befolgst:
- Wähle „Analysieren“ > „Deskriptive Statistik“ > „Erkunden“.
- Ziehe die zu testende Variable in das Feld „Abhängige Liste“.
- Klicke auf den Reiter „Plots“ und markiere das Kästchen „Normalitätstests mit Plot“.
- Klicke auf „OK“.
SPSS wird dir dann die Ergebnisse liefern, einschließlich der W-Statistik und des p-Werts.
Umsetzung in JASP
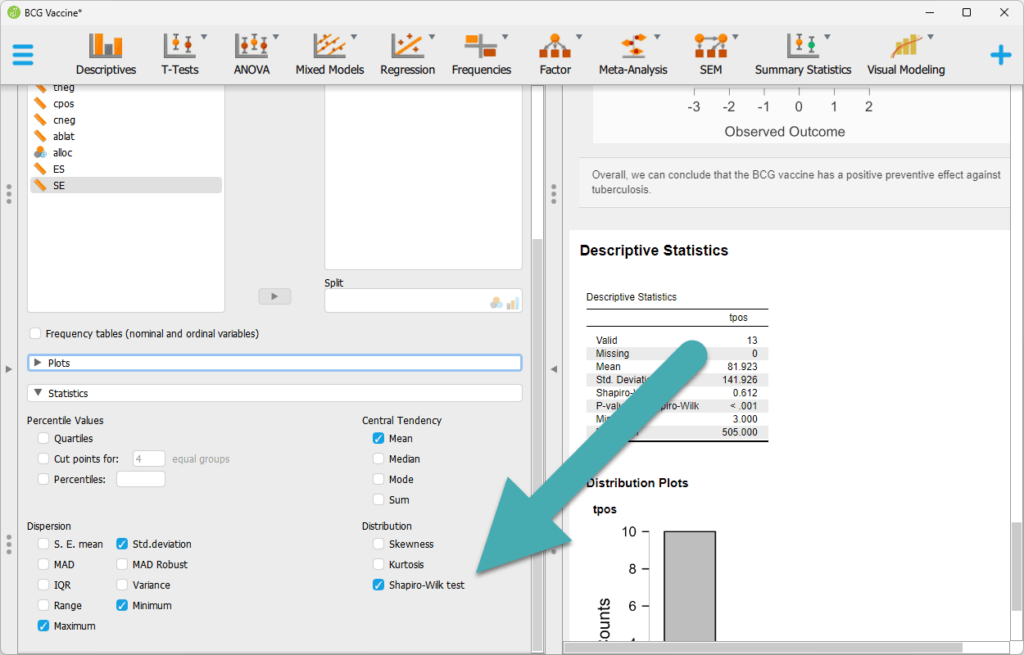
In JASP ist der Shapiro-Wilk-Test genauso einfach:
- Lade deine Daten.
- Wähle „Frequentist“ > „Descriptives“ > „Descriptive Statistics“.
- Ziehe die zu testende Variable in das Feld „Variables“.
- Markiere das Kästchen für „Shapiro-Wilk“ unter „Distribution tests“.
- Die Ergebnisse werden in der Ergebnisansicht angezeigt.
Umsetzung in PSPP
In PSPP kannst du den Shapiro-Wilk-Test durchführen, indem du:
- Deine Daten öffnest oder eingibst.
- „Analyze“ > „Non-parametric Tests“ > „Explore“ wählst.
- Die zu testende Variable im Feld „Dependent List“ auswählst.
- Den Reiter „Plots“ anklickst und „Normality plots with tests“ auswählst.
- Auf „OK“ klickst.
Die Ergebnisse, einschließlich W-Statistik und p-Wert, werden im Ausgabefenster angezeigt.
Wie interpretiert und reported man den Shapiro-Wilk Test?
Nehmen wir an, du hast einen W-Wert von 0,98 und einen p-Wert von 0,25. Das bedeutet, dass die W-Statistik nahe an 1 liegt und der p-Wert über 0,05 ist. Daher kannst du davon ausgehen, dass die Daten normalverteilt sind.
Die Interpretation des Shapiro-Wilk-Tests ist unkompliziert. Wenn der W-Wert nahe an 1 liegt und der p-Wert über 0,05 ist, deutet dies auf eine Normalverteilung der Daten hin. Ist der p-Wert unter 0,05, weisen die Daten wahrscheinlich nicht auf eine Normalverteilung hin. In diesem Fall könnten andere Analysemethoden oder Transformationen der Daten erforderlich sein.
Wenn du die Ergebnisse des Shapiro-Wilk-Tests in APA-Format berichten möchtest, kannst du folgende Struktur verwenden:
„Der Shapiro-Wilk-Test zeigte, dass die Daten normalverteilt waren, W = 0,98, p > 0,05.“
Dabei ersetzt du die Werte mit den tatsächlichen Ergebnissen deines Tests.
Conclusio
Der Shapiro-Wilk-Test ist ein nützliches Werkzeug, um zu überprüfen, ob deine Daten normalverteilt sind. Er ist in vielen Statistikprogrammen wie R, SPSS, JASP und PSPP einfach durchzuführen und zu interpretieren. Das Verstehen und Anwenden des Tests kann dir helfen, die richtigen Analysen für deine Daten auszuwählen und gültige Schlussfolgerungen zu ziehen. Ob du nun eine wissenschaftliche Studie durchführst oder Daten für ein Geschäftsprojekt analysierst, der Shapiro-Wilk-Test ist ein wichtiger erster Schritt in vielen statistischen Analysen. Er wird dir helfen, Vertrauen in deine Daten und die darauf basierenden Entscheidungen zu haben.