In dieser Übung lernst du, wie du mit der einfaktoriellen Varianzanalyse in R prüfst, ob sich die durchschnittliche Arbeitszufriedenheit zwischen drei Abteilungen signifikant unterscheidet. Du wirst die Daten manuell aufbereiten, die Voraussetzungen der ANOVA überprüfen und die Analyse inklusive eines Tukey-Post-hoc-Tests durchführen. Diese praxisnahe Aufgabe hilft dir, statistische Methoden gezielt auf reale Fragestellungen anzuwenden.
Angabe: Einfaktorielle Varianzanalyse in R
Ein Unternehmen möchte untersuchen, ob die durchschnittliche Arbeitszufriedenheit zwischen drei Abteilungen eines Unternehmens unterschiedlich ist.
Dafür bekommst du die folgenden Daten geliefert.
| Abteilung | Zufriedenheitswerte |
|---|---|
| A | 4.2, 4.5, 4.7, 4.3, 4.6 |
| B | 3.8, 3.9, 4.0, 3.7, 3.9 |
| C | 4.1, 4.0, 4.2, 4.1, 4.3 |
Aufgabenstellung:
- Bringe die Daten manuell in ein Format, mit dem du gut weiterarbeiten kannst
- Stelle klar, wieso hie die One-Way-ANOVA der richtige Zugang ist.
- Prüfe die Voraussetzungen für die Durchführung einer One-Way-ANOVA.
- Führe die One-Way-ANOVA durch und interpretiere das Ergebnis.
- Falls signifikante Unterschiede vorliegen, führe einen Tukey-Post-hoc-Test durch und interpretiere die Ergebnisse.
Lösung zur Übung: Einfaktorielle Varianzanalyse in R
Die Lösung im Video
Das komplette R-Skript
# Daten laden
# Abteilung | Zufriedenheit
df <- data.frame(Abteilung = as.factor(c(rep("A", 5), rep("B", 5), rep("C", 5))),
Zufriedenheit = c(4.2, 4.5, 4.7, 4.3, 4.6, 3.8, 3.9, 4.0, 3.7, 3.9, 4.1, 4.0, 4.2, 4.1, 4.3))
head(df)
str(df)
# ANOVA
ergebnis <- aov(formula = Zufriedenheit ~ Abteilung , data = df)
summary(ergebnis)
# Voraussetzungen testen
## Varianzhomogenität
library(car)
leveneTest(df$Zufriedenheit, df$Abteilung)
## Normalverteilung
shapiro.test(df[df$Abteilung == "A", "Zufriedenheit"])
shapiro.test(df[df$Abteilung == "B", "Zufriedenheit"])
shapiro.test(df[df$Abteilung == "C", "Zufriedenheit"])
# Visuelle ÜBerprüfung
hist(df[df$Abteilung == "A", "Zufriedenheit"])
hist(df[df$Abteilung == "B", "Zufriedenheit"])
hist(df[df$Abteilung == "C", "Zufriedenheit"])
# Posthoc Tests
TukeyHSD(ergebnis)
# Nichtparametrische Alternative: KW
kruskal.test(formula = Zufriedenheit ~ Abteilung , data = df)
# Grafisch
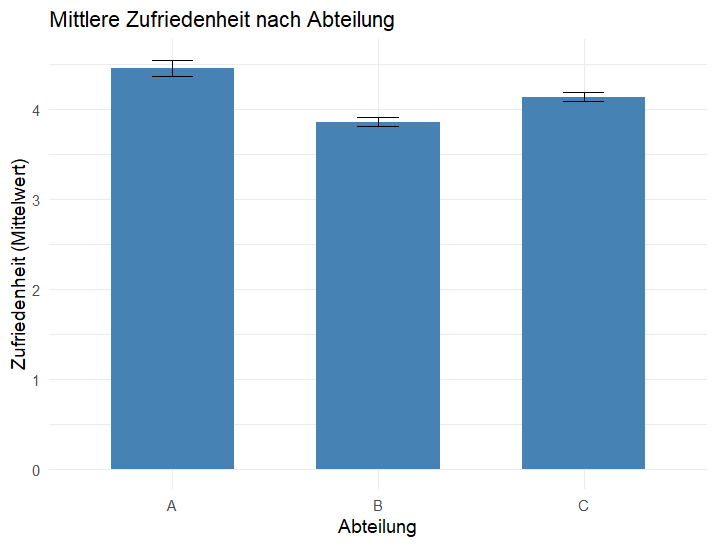
library(ggplot2)
ggplot(df, aes(x = Abteilung, y = Zufriedenheit)) +
stat_summary( # fasst zusammen
fun = mean, # hier: Mittelwert
geom = "bar", # Zeichne Balken
fill = "steelblue",
width = 0.6
) +
stat_summary(
fun.data = mean_se, # Mittelwert ± Fehlerbalken (SE)
geom = "errorbar",
width = 0.2
) +
labs(
title = "Mittlere Zufriedenheit nach Abteilung",
x = "Abteilung",
y = "Zufriedenheit (Mittelwert)"
) +
theme_minimal(base_size = 14)
Grafik
Alles klar?
Ich hoffe, der Beitrag war für dich soweit verständlich. Wenn du weitere Fragen hast, nutze bitte hier die Möglichkeit, eine Frage an mich zu stellen!