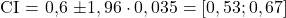Statistische Schätzung ist ein zentrales Konzept in der Datenanalyse. Sie ermöglicht es, aus Stichprobendaten Rückschlüsse auf die gesamte Population zu ziehen. Dabei unterscheidet man zwischen Punktschätzungen (z. B. Mittelwert) und Intervallschätzungen (z. B. Konfidenzintervalle), die die Unsicherheit einer Schätzung berücksichtigen.
Was ist Schätzung überhaupt?
Stell dir vor, du willst herausfinden, wie zufrieden Studierende an deiner Uni mit der Mensa sind. Du kannst unmöglich alle Studierenden befragen, oder? Stattdessen befragst du 50 zufällig ausgewählte Personen. Die Ergebnisse aus dieser Stichprobe nutzt du, um etwas über die gesamte Studierendenschaft zu sagen.
Statistische Schätzung bedeutet genau das: Mit Daten aus einer Stichprobe versuchen wir, etwas über die gesamte Population (also alle) herauszufinden. Das Ziel ist, Werte – sogenannte Parameter – zu schätzen, wie zum Beispiel den Durchschnitt (Mittelwert) oder den Anteil zufriedener Studierender.
Grundlagen der Punktschätzung
Was ist eine Punktschätzung?
Eine Punktschätzung ist ein einzelner Wert, der als Schätzung für einen unbekannten Parameter dient. Nehmen wir unser Mensa-Beispiel: Wenn 50 Studierende befragt werden und der durchschnittliche Zufriedenheitswert 4,2 von 5 beträgt, dann ist 4,2 unsere Punktschätzung für den Durchschnitt aller Studierenden.
Eigenschaften guter Schätzer
Nicht alle Schätzungen sind gleich gut. Ein guter Schätzer sollte die folgenden Eigenschaften haben:
- Erwartungstreue (Unbiasedness): Der geschätzte Wert sollte im Durchschnitt den wahren Wert treffen. Das heißt: Wenn wir die Umfrage tausendmal wiederholen, sollte der Durchschnitt aller Schätzungen nahe am tatsächlichen Wert liegen.
- Effizienz: Ein effizienter Schätzer hat eine geringe Streuung, das heißt, die Schätzwerte liegen nah beieinander.
- Konsistenz: Mit einer größeren Stichprobe wird die Schätzung immer genauer.
- Suffizienz: Ein Schätzer nutzt alle relevanten Informationen in den Daten.
Beispiel: Schätzung des Mittelwerts
Der Mittelwert x̄ ist eine der bekanntesten Punktschätzungen. Er wird berechnet, indem man die Summe aller Werte durch die Anzahl der Werte teilt. Mathematisch sieht das so aus (siehe auch unsere Diskussion der Lagemaße):

Grundlagen der Intervallschätzung
Was ist ein Konfidenzintervall?
Eine Intervallschätzung liefert nicht nur einen Punkt, sondern einen Bereich, in dem der wahre Wert mit hoher Wahrscheinlichkeit liegt. Beispiel: Du schätzt, dass der Durchschnitt aller Studierendenzufriedenheit zwischen 4,0 und 4,4 liegt. Diesen Bereich nennt man Konfidenzintervall.
Das Wichtigste: Ein 95%-Konfidenzintervall bedeutet, dass in 95% von (unendlich oft) gezogenen Stichproben der Populationsmittelwert in diesem Intervall zu finden ist. Manchmal findet man auch die unsaubere Formulierung , dass der Populationsmittelwert mit einer 95% Wahrscheinlichkeit in diesem Bereich liegt. Das ist technisch falsch (der Populationsmittelwert „hat“ keine Wahrscheinlichkeit), aber führt überlicher Weise zu denselben Interpretationen.
Warum Konfidenzintervalle?
Punktschätzungen allein sind oft nicht genug, weil sie keine Auskunft über die Unsicherheit geben. Ein Konfidenzintervall zeigt, wie präzise die Schätzung ist. Ein enger Bereich (z. B. 4,0–4,4) zeigt eine genauere Schätzung als ein breiter Bereich (z. B. 3,5–4,7).
Wie berechnet man ein Konfidenzintervall?
Der Standardfehler gibt an, wie stark der geschätzte Wert (z. B. der Mittelwert) von Stichprobe zu Stichprobe schwankt. Je größer die Stichprobe, desto kleiner wird der Standardfehler – und desto präziser ist die Schätzung.
Beispiel: Stell dir vor, du würfelst zehnmal und berechnest den Mittelwert der Augen. Dann wiederholst du das hundertmal. Die Mittelwerte der zehn Würfe werden stärker schwanken als die Mittelwerte aus hundert Würfen. Deshalb gilt: Mehr Daten = präzisere Schätzungen.
Für den Mittelwert eines Merkmals wird das Intervall wie folgt berechnet:
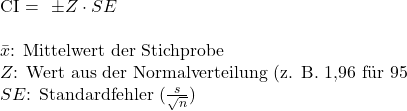
Beispiel: Angenommen, der Mittelwert der Zufriedenheit ist 4,2, die Standardabweichung 0,5 und die Stichprobengröße 50. Der Standardfehler ist dann:
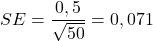
Das 95%-Konfidenzintervall wäre:
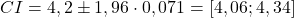
Praxisbeispiele und Anwendungen
Beispiel 1: Durchschnittsalter von Studierenden schätzen
Du möchtest wissen, wie alt Studierende an deiner Uni im Durchschnitt sind. Du ziehst eine Stichprobe von 30 Personen und berechnest den Mittelwert:
- Alter der Studierenden: 18, 19, 20, …, 22
- Mittelwert: x̄ = 20,5
- Standardabweichung: s = 1,5 Jahre
- Konfidenzintervall (95%):
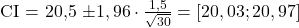
Beispiel 2: Umfragen und Zufriedenheit
Eine Umfrage unter 200 Studierenden ergibt, dass 60% zufrieden mit der Mensa sind. Der Standardfehler für einen Anteil wird berechnet als:
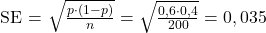
Das Konfidenzintervall beträgt: