Eine theoretische Verteilung beschreibt, wie die Werte einer Zufallsvariablen verteilt oder angeordnet sind. Das Verständnis von Verteilungen ist entscheidend, da sie Einblicke in die Eigenschaften von Datensätzen geben und uns helfen, Vorhersagen über zukünftige Beobachtungen zu treffen. Es gibt verschiedene Arten von Verteilungen, jede mit einzigartigen Eigenschaften und Anwendungen. In diesem Artikel erkläre ich Dir einige der wichtigsten Verteilungen und gebe praktische Beispiele, um das Verständnis zu vertiefen.
Arten von Verteilungen
Eines vorweg: Wir beschäftigen uns hier mit theoretischen Verteilungen. Diese sind zu Unterscheiden von empirischen Verteilungen, die auf tatsächlich beobachteten Daten beruhen. Die Formen können natürlich ähnlich sein, aber die empirischen Daten folgen üblicher Weise nicht ganz so „sauber“ dem Verlauf der theoretischen Verteilung.
https://www.youtube.com/watch?v=OezBjGTT6GQ
Normalverteilung
Die Normalverteilung, oft als „Glockenkurve“ bezeichnet, ist symmetrisch um ihren Mittelwert.
Merkmale:
- Eingipfelig (unimodal)
- Der Mittelwert (Durchschnitt) ist gleich dem Median (Zentralwert) und dem Modus (häufigster Wert).
- Etwa 68 % der Daten liegen innerhalb einer Standardabweichung vom Mittelwert.
Beispiel: Die Körpergröße von erwachsenen Männern folgt in der Regel einer Normalverteilung. Das bedeutet, dass die meisten Männer eine Körpergröße nahe dem Durchschnitt haben, während extrem große oder kleine Männer seltener vorkommen.
In R kannst du eine Normalverteilung mit diesen Code erzeugen und ausgeben:
# Normalverteilung
set.seed(123)
data_norm <- rnorm(1000, mean = 170, sd = 10)
# Histogramm plotten
hist(data_norm, breaks = 30, probability = TRUE, main = "Normalverteilung (Körpergröße)", xlab = "Körpergröße in cm", col = "#47abb2")
# Dichtekurve hinzufügen
lines(density(data_norm), col = "#03083b", lwd = 2)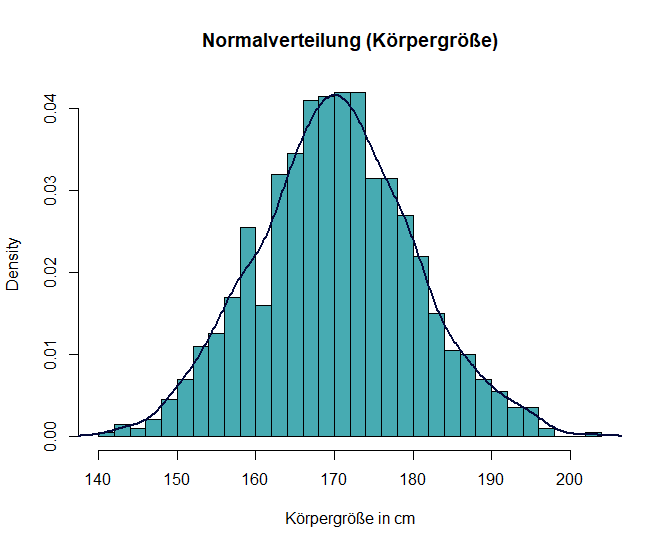
Binomialverteilung
Die Binomialverteilung beschreibt die Anzahl von Erfolgen in einer festen Anzahl von Versuchen, bei denen es zwei mögliche Ergebnisse gibt (Erfolg/Misserfolg).
Merkmale:
- Sie wird durch die Parameter n (Anzahl der Versuche) und p (Wahrscheinlichkeit für einen Erfolg) definiert.
Beispiel: Stell Dir vor, Du wirfst eine Münze 10 Mal und zählst, wie oft Kopf erscheint. Die Anzahl der Köpfe in diesen 10 Würfen folgt einer Binomialverteilung. Wenn Du die Münze oft genug wirfst, kannst Du beobachten, dass das Ergebnis immer näher an den erwarteten Durchschnittswert von fünf Köpfen kommt.
In R kannst du eine Binominalverteilung mit diesen Code erzeugen und ausgeben:
# Binomialverteilung
set.seed(123)
data_binom <- rbinom(1000, size = 10, prob = 0.5)
# Histogramm plotten
hist(data_binom, breaks = 10, probability = TRUE, main = "Binomialverteilung (10 Münzwürfe)", xlab = "Anzahl Kopf", col = "#47abb2")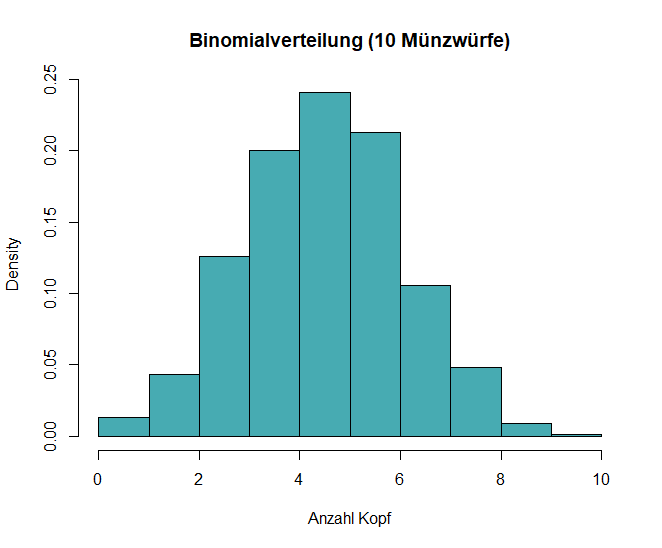
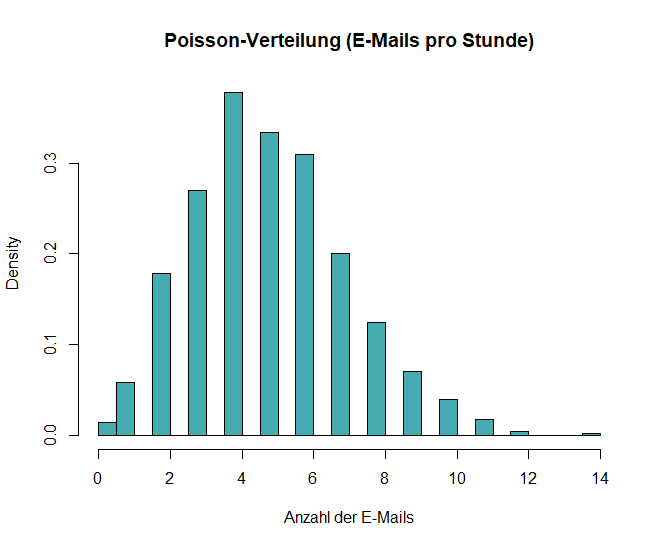
Poisson-Verteilung
Die Poisson-Verteilung modelliert die Anzahl von Ereignissen, die in einem festen Intervall auftreten, wenn diese Ereignisse unabhängig voneinander geschehen.
Merkmale:
- Sie wird durch λ (Lambda) definiert, das die durchschnittliche Rate darstellt, mit der Ereignisse auftreten.
Beispiel: Stell Dir vor, Du arbeitest in einem Büro und möchtest wissen, wie viele E-Mails Du durchschnittlich pro Stunde erhältst. Diese Anzahl kann durch eine Poisson-Verteilung beschrieben werden, da die E-Mails unabhängig voneinander eintreffen und es eine durchschnittliche Ankunftsrate gibt.
In R kannst du eine Poisson-Verteilung mit diesen Code erzeugen und ausgeben:
# Poisson-Verteilung
set.seed(123)
data_pois <- rpois(1000, lambda = 5)
# Histogramm plotten
hist(data_pois, breaks = 30, probability = TRUE, main = "Poisson-Verteilung (E-Mails pro Stunde)", xlab = "Anzahl der E-Mails", col = "#47abb2")
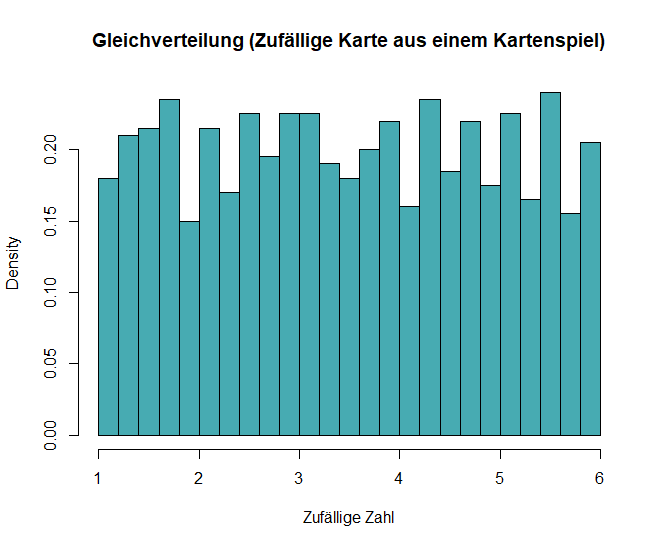
Gleichverteilung
Bei einer Gleichverteilung (oder auch uniforme Verteilung genannt) sind alle Ergebnisse über einen bestimmten Bereich gleich wahrscheinlich.
Merkmale:
- Sie kann diskret oder kontinuierlich sein. Zum Beispiel führt das Würfeln mit einem fairen Würfel zu einer Gleichverteilung über die Zahlen 1 bis 6, da jede Zahl die gleiche Wahrscheinlichkeit hat, geworfen zu werden.
Beispiel: Wenn Du aus einem gut gemischten Kartenspiel eine Karte ziehst, hat jede Karte die gleiche Wahrscheinlichkeit, ausgewählt zu werden. Das ist ein typisches Beispiel für eine diskrete Gleichverteilung.
In R kannst du eine Gleichverteilung mit diesen Code erzeugen und ausgeben:
# Gleichverteilung
set.seed(123)
data_unif <- runif(1000, min = 1, max = 6)
# Histogramm plotten
hist(data_unif, breaks = 30, probability = TRUE,
main = "Gleichverteilung (Zufällige Karte aus einem Kartenspiel)", xlab = "Zufällige Zahl", col = "#47abb2")
Exponentialverteilung
Die Exponentialverteilung beschreibt die Zeit bis zum Eintreten eines Ereignisses, z. B. die Wartezeit zwischen unabhängigen Ereignissen, die mit einer konstanten durchschnittlichen Rate auftreten.
Merkmale:
- Diese Verteilung hat die Eigenschaft der „Gedächtnislosigkeit“ – frühere Ereignisse haben keinen Einfluss auf die zukünftige Wahrscheinlichkeit.
Beispiel: Stell Dir vor, Du wartest an einer Bushaltestelle, und die Busse kommen im Durchschnitt alle 15 Minuten. Die Zeit zwischen den Ankünften der Busse folgt einer Exponentialverteilung, was bedeutet, dass die Wartezeit nach einem Bus unabhängig davon ist, wie lange Du bereits gewartet hast.
In R kannst du eine Exponentialverteilung mit diesen Code erzeugen und ausgeben:
# Exponentialverteilung
set.seed(123)
data_exp <- rexp(1000, rate = 1/15)
# Histogramm plotten
hist(data_exp, breaks = 30, probability = TRUE, main = "Exponentialverteilung (Wartezeit auf Bus)", xlab = "Wartezeit in Minuten", col = "#47abb2")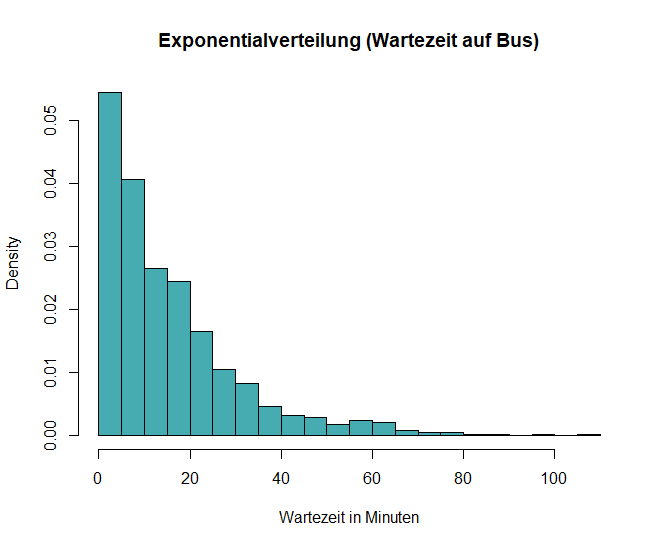
Warum ist das Verständnis von Verteilungen wichtig?
Datenanalyse:
Wenn Du weißt, welche Verteilung zu Deinen Daten passt, kannst Du geeignete statistische Methoden für die Analyse und Interpretation auswählen. Zum Beispiel basieren viele Analysemethoden, wie der t-Test oder die Varianzanalyse (ANOVA), auf der Annahme, dass die Daten einer Normalverteilung folgen.
Hypothesentests:
Viele statistische Tests setzen bestimmte Verteilungen voraus. Wenn Du diese Annahmen verstehst, kannst Du sicherstellen, dass die Schlussfolgerungen, die Du aus statistischen Tests ziehst, gültig sind.
Vorhersagemodelle:
In Bereichen wie Finanzen oder Gesundheitswesen ermöglicht das Wissen über das Verhalten von Daten Analysten, Trends genauer vorherzusagen. Wenn Du z. B. weißt, dass Patientenzahlen im Krankenhaus einer Poisson-Verteilung folgen, kannst Du besser planen, wie viele Ärzte während der Stoßzeiten gebraucht werden.
Simulation
Hier habe ich die wichtigsten Verteilungen auch in Google-Sheets nachgebaut. Dort kannst du nicht nur die Formeln sehen, sondern siehst auch nochmal klar ausgewiesen, was die Parameter sind, die die Funktion beeinflussen (und damit die entsprechende Kurve ergeben).
Hier ist ein praktisches Online-Tool, um mit verschiedenen Population- und Stichprobenparametern herumzuspielen und die Inhalte dieser Lektion zu vertiefen:
Praktische Beispiele aus dem Alltag
- Wenn Du die Testergebnisse von Schülern aus verschiedenen Klassen analysierst, könntest Du feststellen, dass diese einer Normalverteilung folgen. Das hilft Dir als Lehrer, die Leistungsniveaus besser zu verstehen und geeignete Fördermaßnahmen zu ergreifen.
- In der Qualitätskontrolle eines Produktionsbetriebs könnte die Binomialverteilung eingesetzt werden, um zu bestimmen, wie viele defekte Produkte basierend auf einer Stichprobe aus einer großen Produktionsmenge erwartet werden. Das ermöglicht es den Managern, die Qualitätsstandards effizient aufrechtzuerhalten.
- Ein Krankenhaus könnte die Poisson-Verteilung nutzen, um die Anzahl der Patientenankünfte während der Stoßzeiten vorherzusagen. Diese Informationen helfen dabei, Personalentscheidungen zu treffen und sicherzustellen, dass der Service optimal bleibt, ohne das Personal zu überlasten.
Verteilungen zu verstehen, gibt Dir das Handwerkszeug, um komplexe Datensätze zu interpretieren und die zugrunde liegenden Muster zu erkennen, die Deine Entscheidungen in verschiedenen Bereichen unterstützen!
Alles klar?
Ich hoffe, der Beitrag war für dich soweit verständlich. Wenn du weitere Fragen hast, nutze bitte hier die Möglichkeit, eine Frage an mich zu stellen!